

采集复制与抄袭他人网站的内容一直是搜索引擎深恶痛绝的行为,而对于各种抄袭的内容,搜索引擎也都有自己的一套应对方式,比如今年百度刚发布不久的飓风算法,就是百度针对网站采集抄袭行为做出的又一惩罚举措。那么,对于重复的内容,以谷歌为例,搜索引擎是怎样处理比对的呢?

谷歌的员工Gary Illyes在推特上被问到该问题时,表示针对这个内容可以写一篇专门的博文了。针对该问题,Gary先发布了几条推文进行了简单的说明:
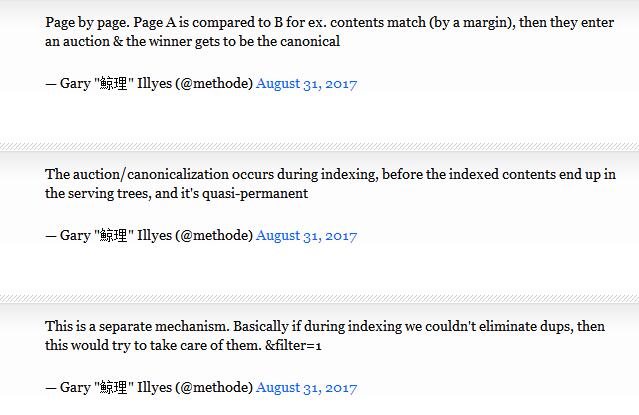
简单翻译说明一下:
谷歌对于重复内容的比对是以页面级别来进行的,页面A与页面B基于某种范围来进行内容比对,之后谷歌会判定出哪一个为权威版本。而这一步发生在索引过程中,即在将抓取内容存放入索引库之前就已经发生,并且这个比对结果是准永久的,通常不会发生变化。
然而如果谷歌无法在索引过程中消除掉重复的内容,即无法准确判定哪一个为权威版本时,谷歌在存放入索引库后,还有另一套过滤机制来进行处理。
新锐建站补充:对于重复内容,谷歌是按照页面级别来进行比对的。也就因此,除了文本内容、发布时间,页面上其他的附加价值,比如更多的相关性内链补充,更加多的相关信息的外链,甚至页面速度等等用户体验相关,都可以作为权威版本的评判标准。与此同时,来自大的知名度高的权威站点的内容,也更容易被认为是权威版本。

