谷歌否认在网站质量算法上应用机器学习
谷歌在机器学习的发展上一直是行业的领头羊,基于机器学习发展出的人工智能alphago与围棋高手之间的围棋比赛胜负也一次又一次成为了讨论量相当多的话题。关于未来的搜索引擎,有人曾经预测过,当启用机器学习作为搜索引擎的辅助或管理后,搜索引擎通过机器学习,将学会自己判断网站与其内容的质量,并将不断地进化优化算法,甚至会自己得出一套关于网站的用户体验评价。但是据最新消息看来,机器学习应用到具体算法上的改进还有一段时日。
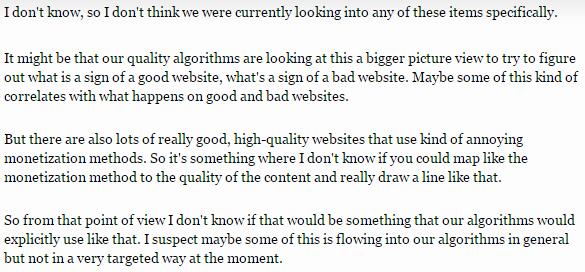
来自谷歌的John Mueller推特上关于“机器学习是否会应用到”回复表示:在关于网站质量的算法上,谷歌并没有应用机器学习。这些质量算法包括:企鹅算法(对过度seo的网站进行惩罚),熊猫算法(惩罚低质量内容网站)等等。然而John Mueller在回复中特意解释了机器学习现在确实可能在搜索引擎上有所应用。 “在判断整个站点的质量好坏上,机器学习或许会得到应用。但在特定具体的惩罚机制上面,并不会使用机器学习。”他解释道:“对于低质量的内容与过度seo等等的惩罚算法,并没有一个具体明确的标准或限制。在一些评级好的站点上,同样可能会存在垃圾内容与过度seo的现象。由于无法明确的给出具体的标准,因此在具体针对性的算法上,运用机器学习进行自我判断在现在来看还是不明智的。”
以下是推文问答的原文截图:
推特上的提问
John Mueller的回答